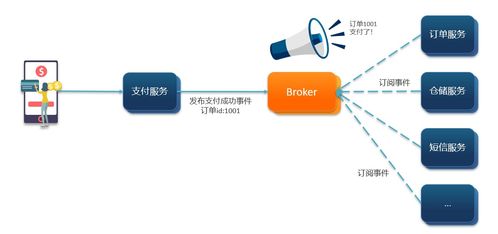
在基于微服務架構的信息系統集成服務(如CSDN平臺可能構建的復雜系統)中,服務間通過消息隊列(如RabbitMQ、Kafka、RocketMQ)進行異步通信是解耦和提升系統彈性的核心模式。這種異步、間接的調用方式也給調試帶來了巨大挑戰。消息的流轉過程變得不透明,問題可能出現在生產者、消費者或消息隊列自身。本文將系統地闡述針對此場景的調試方法論、工具與實踐,幫助開發者高效定位和解決問題。
一、核心調試挑戰
- 調用鏈斷裂:傳統的同步調用(如HTTP/RPC)有清晰的調用棧和鏈路ID,而消息隊列異步通信后,鏈路追蹤變得困難,難以關聯生產事件與消費事件。
- 狀態非即時:問題發生時,消息可能已在隊列中,或已被消費且狀態已改變,現場難以復現。
- 環境依賴復雜:調試需同時考慮生產者服務、消息隊列中間件、消費者服務三者的狀態與配置。
- 數據一致性難驗證:在分布式事務最終一致性的場景下,消息的可靠投遞、冪等消費、死信處理等邏輯是否正確,需要系統化驗證。
二、系統化調試策略與方法
1. 強化可觀測性建設(基礎)
- 結構化日志:在生產者和消費者中,為每一條關鍵消息分配唯一的業務標識符(如訂單ID)和消息追蹤ID(可與鏈路追蹤系統結合)。日志中需明確記錄:消息生產/消費時間、消息體關鍵摘要、隊列主題/標簽、處理結果(成功、失敗及原因)。
- 分布式鏈路追蹤集成:將消息隊列作為鏈路中的一個組件進行集成。例如,使用SkyWalking、Jaeger等工具,在生產和消費端注入追蹤上下文,使得一條消息的完整生命周期可以在追蹤系統中可視化呈現,清晰看到跨服務的延遲和瓶頸。
- 豐富指標監控:監控消息隊列的關鍵指標,如隊列深度、入隊/出隊速率、消費者數量、錯誤/重試/死信消息數量。設置告警閾值,以便在問題影響擴大前及時發現。
2. 本地與測試環境調試技巧
- 搭建完整本地環境:使用Docker Compose或K8s在本地輕量級部署消息隊列中間件及其管理界面(如RabbitMQ Management Plugin、Kafka Manager),便于直接查看隊列狀態和消息內容。
- 消息“窺探”與重放:
- 利用管理界面或命令行工具直接查看隊列中的消息內容(注意隱私和安全)。
- 將生產環境的問題消息導出(如死信隊列中的消息),在測試環境中構造并重放,復現問題。
- 開發臨時的“調試消費者”訂閱特定隊列,僅打印或存儲收到的消息,用于驗證消息是否正確投遞。
- 模擬與隔離:
- 模擬生產者:使用腳本或Postman等工具模擬生產者發送特定消息,測試消費者邏輯。
- 隔離消費者:在調試時,可以臨時將特定消費者從業務隊列中移除,或將消息路由到專有的調試隊列,避免干擾線上業務。
3. 針對CSDN類集成服務的特定場景調試
假設場景:CSDN的文章發布服務(生產者)在文章審核通過后,發送消息通知“積分獎勵服務”、“內容搜索索引服務”、“關注者推送服務”(多個消費者)進行后續處理。
- 問題:文章發布成功,但搜索索引未更新。
- 調試步驟:
- 定位環節:檢查鏈路追蹤,確認消息是否已從“文章服務”發出。查看消息隊列監控,確認消息是否進入“搜索索引更新”隊列。
- 檢查消費者:查看“搜索索引服務”的日志,過濾該文章ID,看是否有消費記錄。若無,檢查消費者服務是否正常運行、訂閱主題是否正確、網絡是否連通。
- 分析消息:若有消費記錄但索引未更新,則“窺探”該消息內容,檢查消息格式是否符合消費者預期(如字段缺失、類型錯誤)。同時檢查消費者處理邏輯的日志,看是否有異常拋出但被靜默處理或重試失敗進入死信。
- 驗證端到端:在測試環境,構造一條與生產環境相同的消息(或從死信隊列導出),啟動一個干凈的“搜索索引服務”實例進行消費,觀察其完整處理流程。
4. 利用高級工具與特性
- 死信隊列(DLQ):這是最重要的調試工具之一。配置消費失敗多次重試后自動進入DLQ。定期檢查DLQ中的消息,它們直接指明了消費失敗的具體消息和可能的異常原因。
- 消息追蹤插件:一些消息隊列(如RabbitMQ的Firehose Tracer、Kafka的監控攔截器)可以記錄所有消息的流向,用于深度審計。
- 集成開發環境(IDE)插件:部分IDE有消息隊列相關的插件,支持直接連接、查看和發送測試消息。
三、調試流程
- 現象發現:通過監控告警(如隊列積壓、消費錯誤率上升)或業務反饋(如數據不一致)發現問題。
- 信息收集:立即收集相關時間段的日志(生產者、消費者、消息隊列)、鏈路追蹤數據、隊列監控指標。
- 環節定位:利用可觀測性工具,快速確定問題是出在生產端(未發送?)、傳輸端(隊列丟失?路由錯誤?)、還是消費端(崩潰?邏輯錯誤?)。
- 根因分析:對問題環節進行深入分析。生產/消費端:查看業務日志和異常棧。傳輸端:檢查消息隊列狀態、網絡、配置(交換器、綁定、路由鍵)。
- 復現與驗證:在安全的環境(測試/預發布)中復現問題,驗證修復方案。
- 修復與預防:修復代碼或配置。考慮是否需增加更完善的日志、監控或容錯邏輯(如更合理的重試、死信處理策略),防止同類問題再次發生。
結論
調試微服務間的消息隊列通信,關鍵在于將異步、黑盒的過程通過可觀測性工具變得可視化、可追蹤。建立從日志、指標到鏈路的全方位監控體系是高效調試的基石。結合本地模擬、消息重放、死信隊列分析等具體手段,可以系統化地定位和解決從消息生產、傳輸到消費各個環節的問題。對于像CSDN這樣復雜的集成服務平臺,堅持這套工程實踐能極大提升系統穩定性和團隊排障效率。